 400-8166108
400-8166108
行业动态
在这里,聆听大咖的声音

DeepSeek-R1 模型在 4 张 NVIDIA RTX™ 5880 Ada GPU Generation 显卡配置下,面对短文本生成、长文本生成、总结概括三大实战场景,会碰撞出怎样的性能火花?参数规模差异悬殊的 70B 与 32B 两大模型,在 BF16 精度下的表现又相差几何?本篇四卡环境实测报告,将为用户提供实用的数据支持和性能参考。

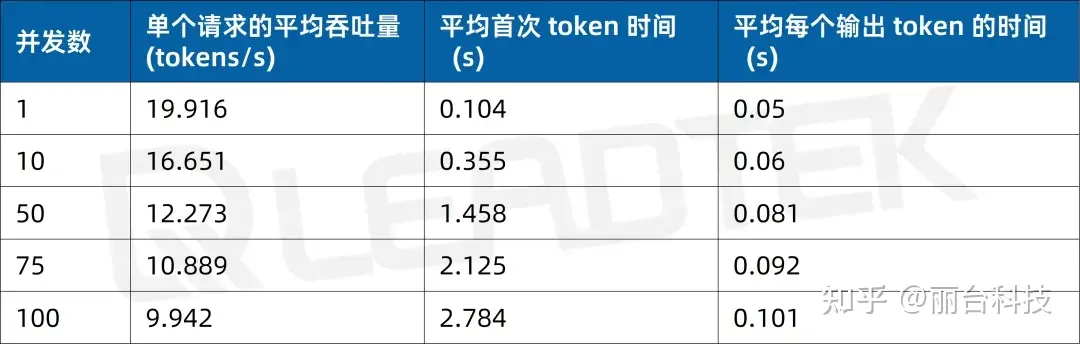
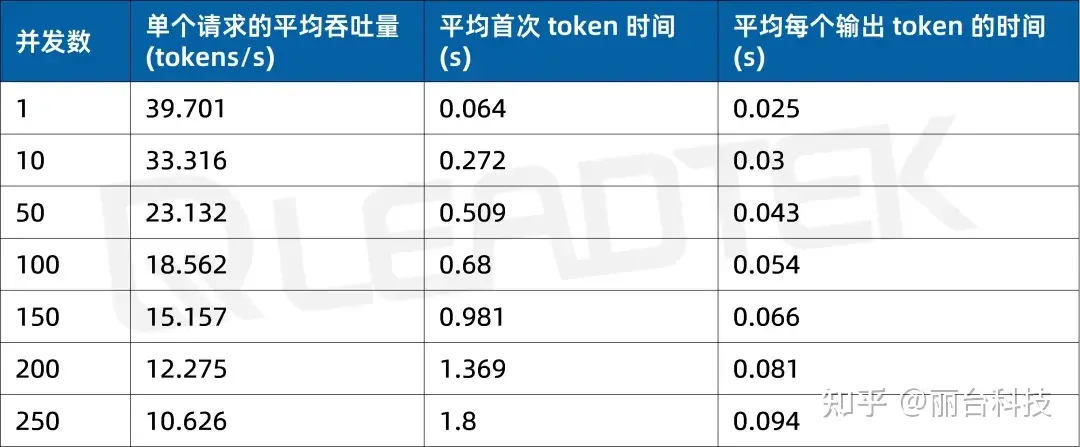
首次 token 生成时间(Time to First Token, TTFT(s))越低,模型响应速度越快;每个输出 token 的生成时间(Time Per Output Token, TPOT(s))越低,模型生成文本的速度越快。
在实际业务部署中,输入/输出 token 的数量直接影响服务性能与资源利用率。本次测试针对三个不同应用场景设计了具体的输入 token 和输出 token 配置,以评估模型在不同任务中的表现。具体如下:
 bbb7469f" style="display:block;max-width:100%;margin:0px auto;cursor:zoom-in;" />
bbb7469f" style="display:block;max-width:100%;margin:0px auto;cursor:zoom-in;" />
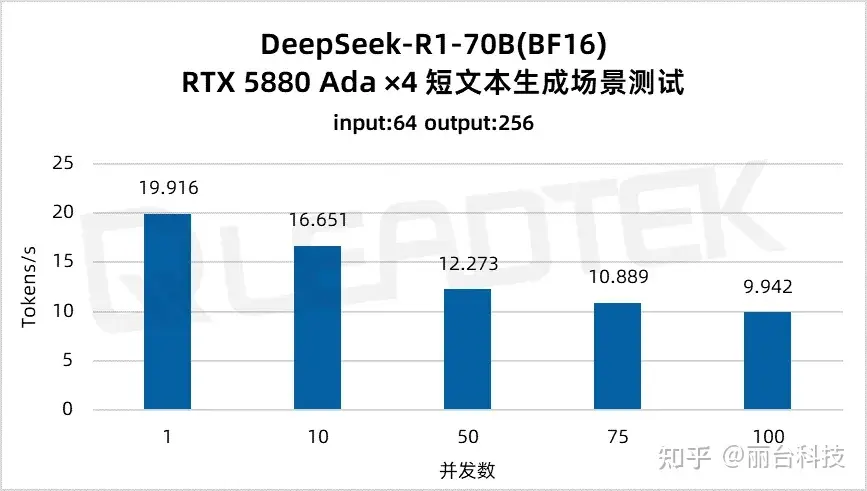
使用 DeepSeek-R1-70B(BF16),单请求吞吐量约 19.9 tokens/s,并发 100 时降至约 9.9 tokens/s(约为单请求的 50%)。最佳工作区间为低并发场景(1-50 并发)。
使用 DeepSeek-R1-32B(BF16),单请求吞吐量达约 39.5 tokens/s,并发 100 时仍保持约 18.1 tokens/s,能够满足高并发场景(100 并发)。


使用 DeepSeek-R1-70B(BF16),单请求吞吐量约 20 tokens/s,并发 100 时降至约 8.8 tokens/。最佳工作区间为低并发场景(1-50 并发)。

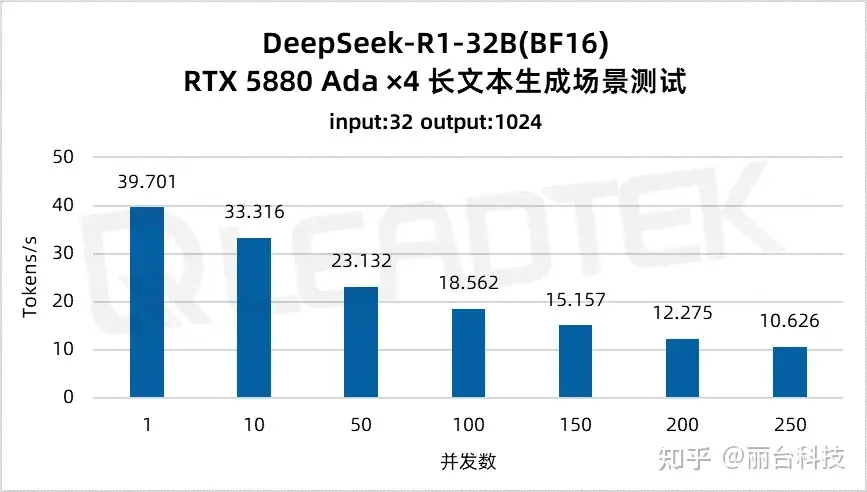
使用 DeepSeek-R1-32B(BF16),单请求吞吐量达约 39.7 tokens/s,并发 250 时仍保持约 10.6 tokens/s,能够满足较高并发场景(250 并发)。
使用 DeepSeek-R1-70B(BF16),单请求吞吐量约 18.7 tokens/s,并发 10 时降至约 10.9 tokens/。最佳工作区间为低并发场景(10 并发)。
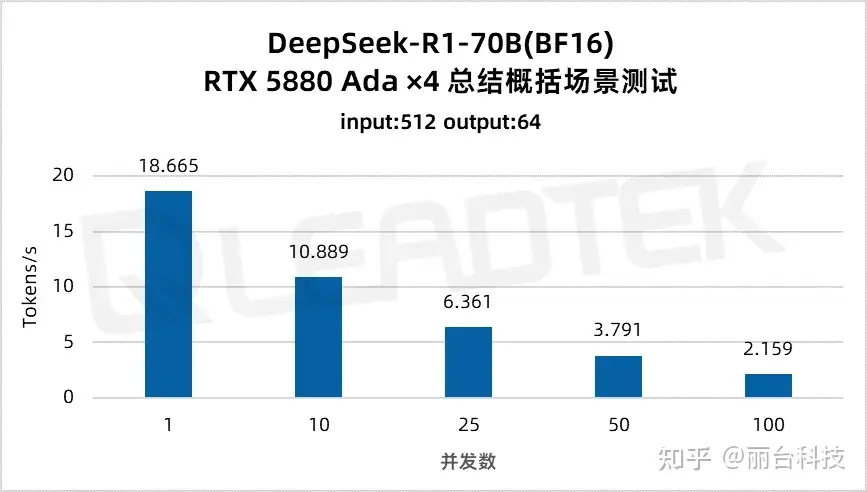
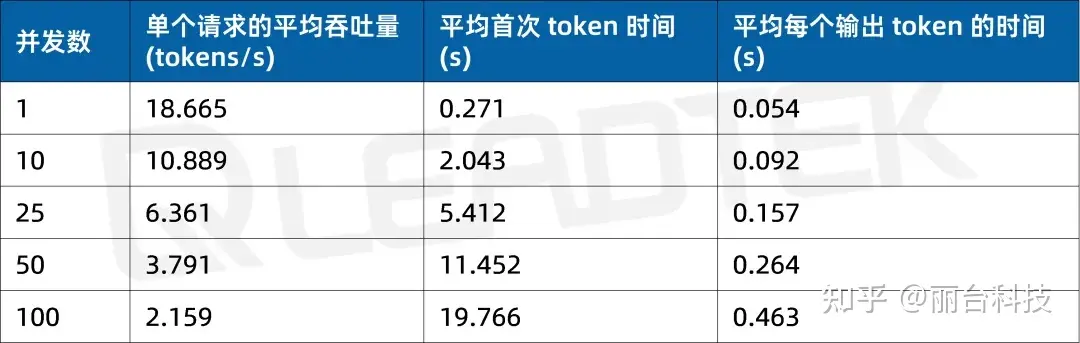
使用 DeepSeek-R1-32B(BF16),单请求吞吐量达约 37 tokens/s,并发 25 时仍保持约 15.3 tokens/s,能够满足中等并发场景(25 并发)。


DeepSeek-R1-70B(BF16) 模型表现:
短文本生成:支持 75 并发量,单请求平均吞吐量>10.9 tokens/s
长文本生成:支持 50 并发量,单请求平均吞吐量>12.5 tokens/s
总结概括:支持 10 并发量,单请求平均吞吐量>10.9 tokens/s
DeepSeek-R1-32B(BF16) 模型表现:
短文本生成:支持 100 并发量,单请求平均吞吐量>18.1 tokens/s
长文本生成:支持 250 并发量,单请求平均吞吐量>10.6 tokens/s
总结概括:支持 25 并发量,单请求平均吞吐量>15.3 tokens/s
基于 4 卡 RTX 5880 Ada GPU 的硬件配置下:
本次基准测试在统一硬件环境下完成,未采用任何专项优化策略。
本文所有测试结果均由丽台科技实测得出,如果您有任何疑问或需要使用此测试结果,请联系 @丽台科技 。
如需部署 DeepSeek 671B 完整参数版本,欢迎联系 @丽台科技 获取定制化解决方案。
